VAT Skeleton Mode Preview
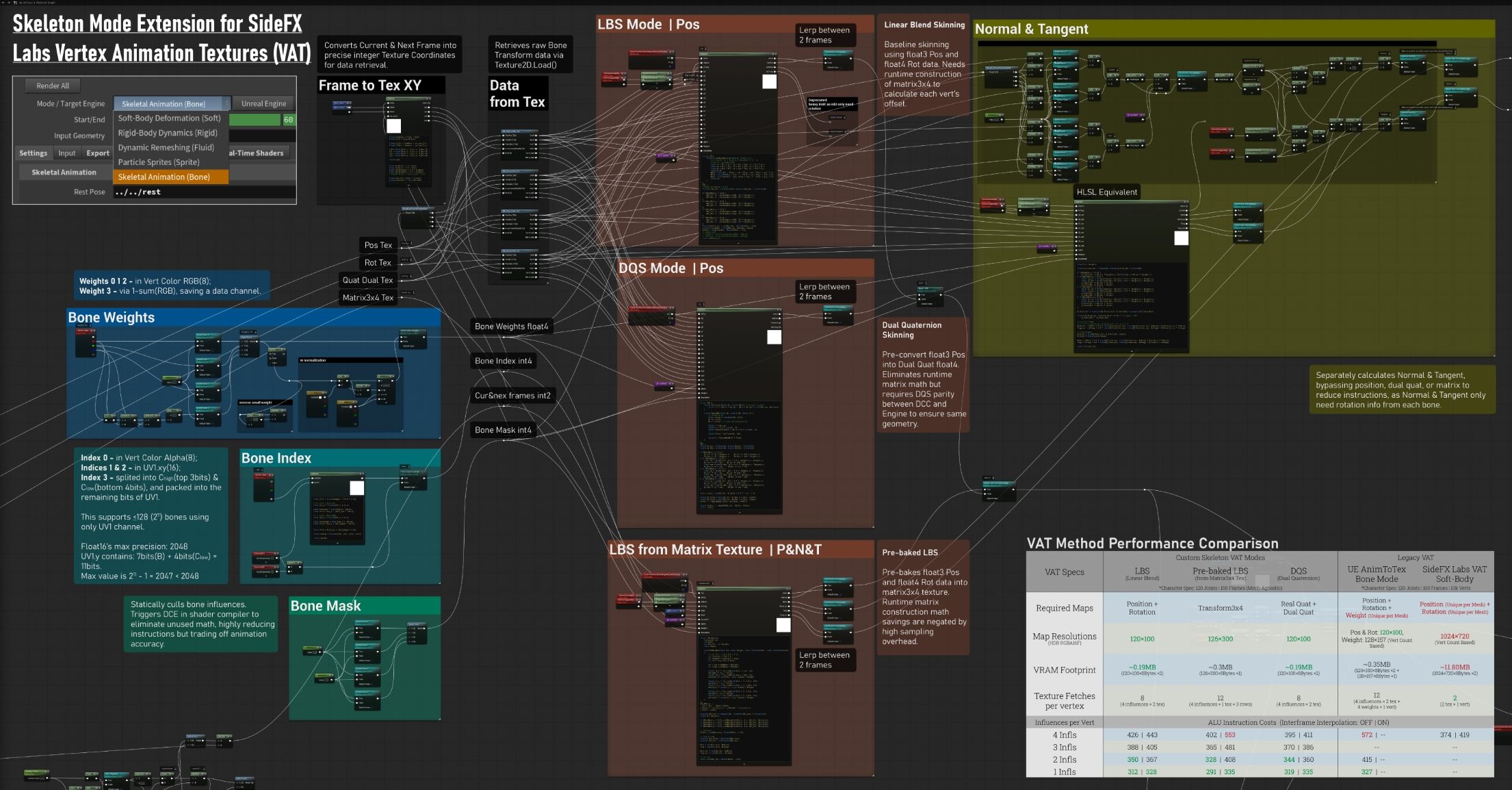
VAT Method Performance Comparison

Proposed Skeleton Mode (The Left 3 Columns) These represent my custom-developed shader mode variants:
Legacy VAT / Control Group (The right 2 Columns):
The Search for Scalability
During my stadium crowds system, I started with SideFX Labs VAT 3.0. While reliable for environment assets, its vertex-centric approach creates massive bottlenecks for crowds.
Every character mesh, sharing identical skeletons, requires their own unique set of baked textures.
As character counts and animation variety grow, the disk space and VRAM footprint explode, making unified animation management impossible.
Seeking a bone-centric alternative, I experimented with Unreal’s AnimToTexture Plugin.
While it technically offers a Bone Mode, the practical experience was proved unstable and difficult to integrate.
It is prone to instability and offers little transparency for troubleshooting transform drifts and lacks the flexibility needed for stable, high-volume batch pipelines.
So a clear objective: to build a transparent, bone-level VAT pipeline that uses runtime GPU skinning to reduce texture bandwidth and increase scalability across different characters who share skeleton.
Skinning data Encoding
Skinning calculations are quite heavy. If we can distribute this workload to the GPU, we can reduce the computational pressure on the CPU.
That’s exactly what VAT does, and we just need to convert the skinning logic to GPU to translate the bone’s transform info to each vertex.
The essence is to implement weight blending calculations within the GPU. The skinning data structure is simple:
struct BoneInfluence
{
float weight[4];
int boneIndex[4];
};Each vertex corresponds to a BoneInfluence, which corresponds to the indices of its bound bones and their associated weights.
And at most four bones linked to each mesh vertex is enough in most case.
Weights
Since all weights sum to 1.0, we only need to store three weights and the forth can be calculated from one minus the first three.
Encoding:
Indices
For the four indices, while we could choose to use Vert Color RGBA8, since they are integers, we can use a more compact method.
If the bone count does not exceed a certain number, we can perform data compression and using additional UVs for storage.
By default, Custom UVs use two 16-bit Half-floats (R16G16F) formats. And 16-bit floats can only represent integers in the range of [0, 2048] exactly without any rounding errors.
Values larger than 2048 will be approximations, not exact integers, which could lead to unexpected transform when we need to fetch the accurate bone index.
By limiting the skeleton to bones (7 bits), we can pack all four bone indices using only the Vertex Alpha and a single UV1 (UV1.x, UV1.y) channel.
Encoding
Precision Check
The most congested channel, UV1.y, contains: 7 bits (Index 2) + 4 bits (Index 3 Low) = 11 bits.
The maximum value is , which perfectly aligns with the 2048 integer precision limit of 16-bit floats, ensuring zero index drift while consuming 50% less UV bandwidth.
Skinning Texture Baking
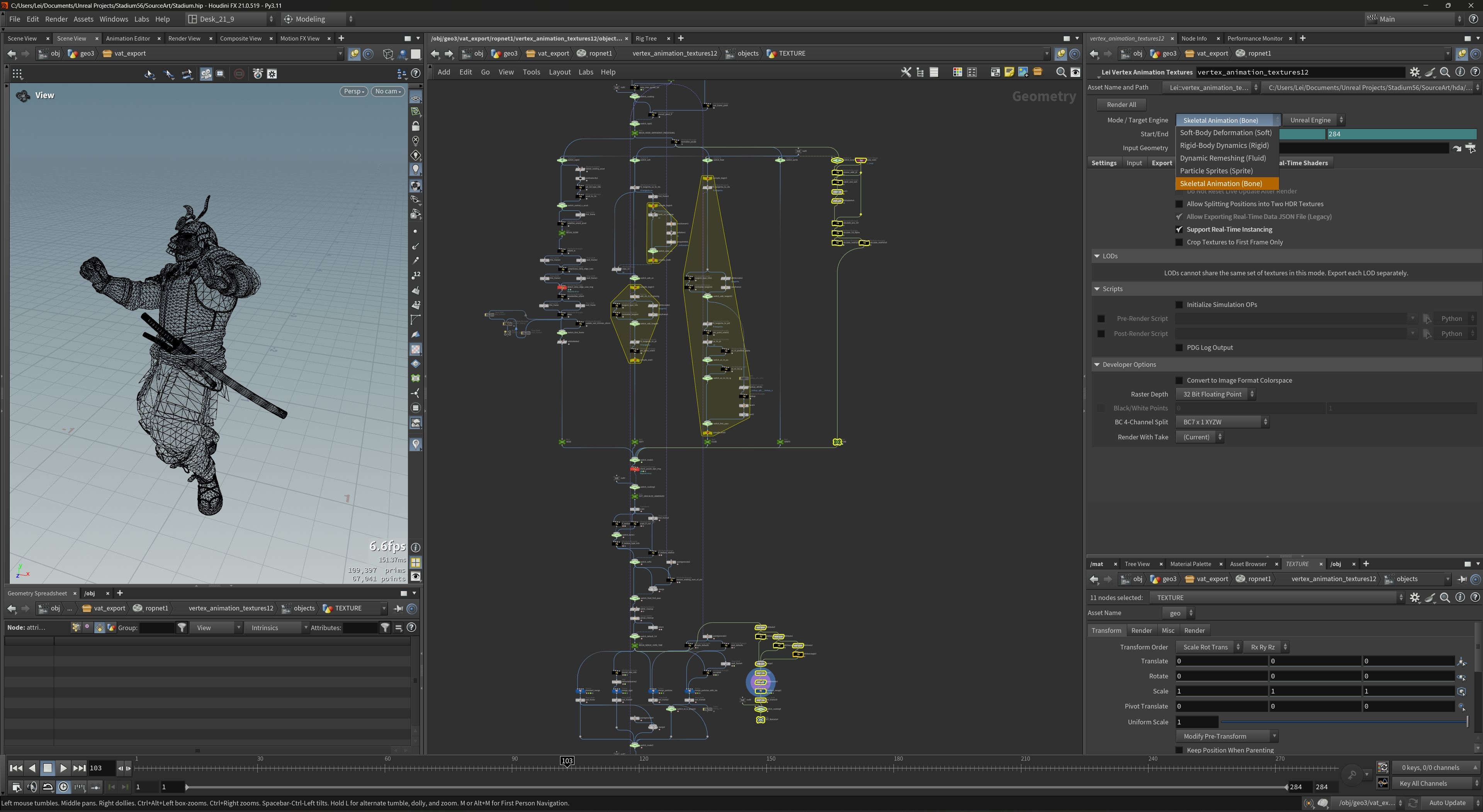
To implement this skeleton-centric workflow, I modified the standard SideFX Labs VAT HDA, adding a dedicated Skeleton Animation mode.
This required a complete overhaul of the baking logic, shifting the focus from per-vertex offsets to relative bone transforms.
VEX Transform Logic
The core of the baker is a suite of VEX wrangles that calculates the delta transform between the bone’s rest pose and its animated state.
By calculating , we derive a local-space transform that isolates the pure animation delta by effectively ‘neutralizing’ the bind pose.
And this transform is mesh-independent, meaning it can be applied to any vertex bound to that bone regardless of the mesh’s unique topology, as long as the underlying skeleton matches.
// Core VEX Snippet
// Rest Matrix
vector rest_P = point(1, "P", @ptnum);
matrix3 rest_rot = point(1, "transform", @ptnum);
matrix m_rest = matrix(rest_rot);
translate(m_rest, rest_P);
// Animation Matrix
vector anim_P = v@P;
matrix3 anim_rot = 3@transform;
matrix m_anim = matrix(anim_rot);
translate(m_anim, anim_P);
// Delta Transform
matrix m_final = invert(m_rest) * m_anim;
// Extract Data to be baked
v@P_out = cracktransform(0, 0, 0, 0, m_final); // Translation T
p@orient_out = normalize(quaternion(matrix3(m_final))); // Rotation QIt is worth noting that m_final could also be baked directly into the texture, then we dont need the shader to calculate it from the float3 T and float4 Q data.
While this would reduce real-time matrix reconstruction costs, it would necessitate an additional row of data per bone to be fetched, increasing the texture sampling count.
This is the Pre-baked LBS mode will be mentioned in later sections.
Shader Development & Optimization
The development of the HLSL skinning solver was a process of extreme optimization.
The initial prototype, burdened by unoptimized indexing and raw data handling, reached a peak of 1663 instructions, which was prohibitive for massive crowd rendering and made the skeleton VAT meaningless.
Through multiple iterations of refactoring and data-packing, the final instruction count was reduced to approximately 300-450 instructions depending on the active skinning mode.
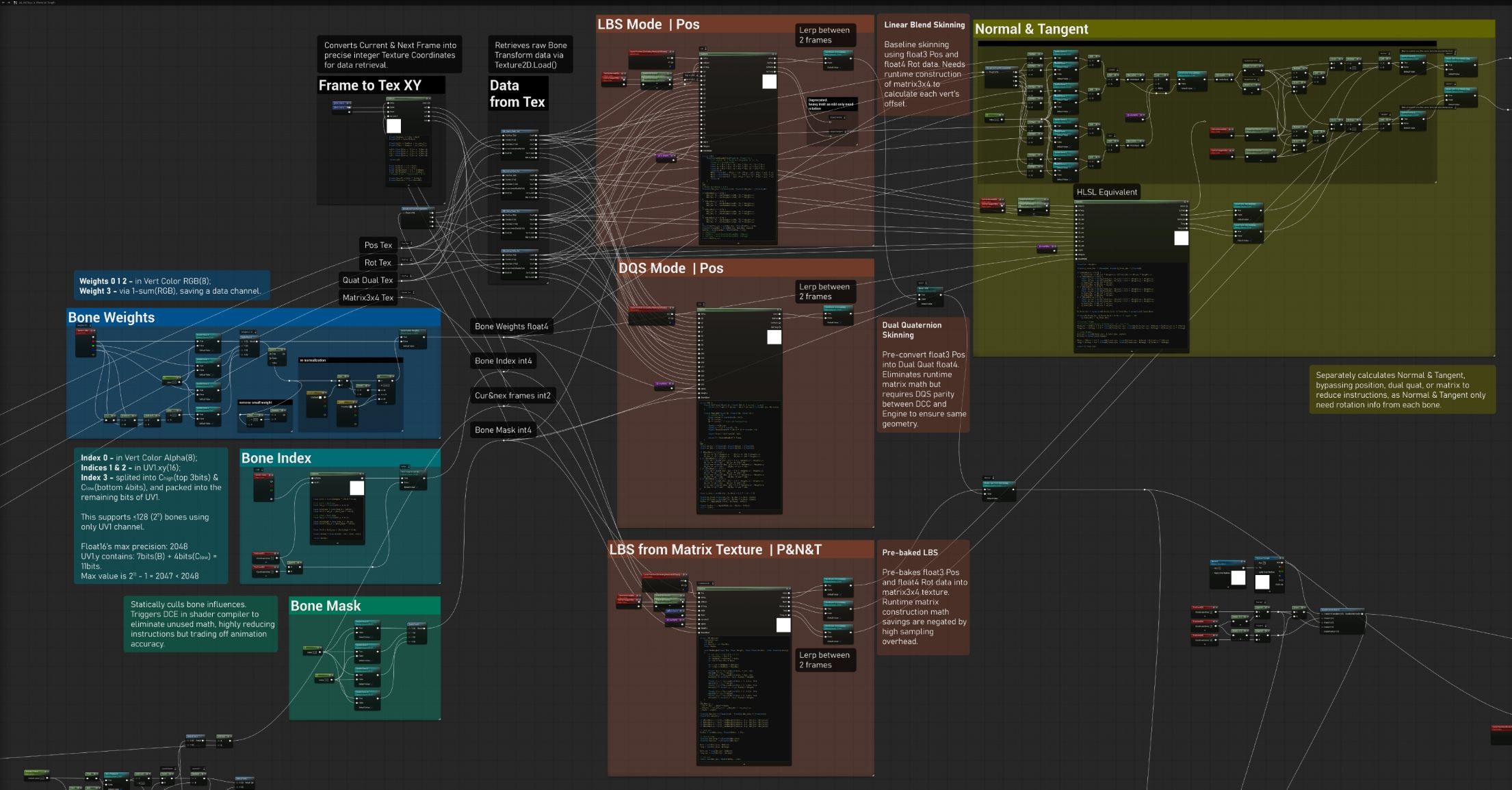
Standard LBS (Linear Blend Skinning)
This was the first workable version. In this mode, the shader fetches rotation (Quaternion) and translation (Vector) for each bone influence and reconstructs the transformation matrix3x4 on the fly.
The Challenge
Matrix reconstruction is math-intensive.
And the workload is exponentially magnified by calculating 4 bone transforms across both current and next frames for temporal interpolation.
Refinement
By centralizing the HLSL logic and decoupling the Normal/Tangent solver from WPO’s matrix calculation,
since orientation only requires rotation data, the Normal/Tangent can be solved directly without the overhead of full matrix construction,
the instruction count dropped from ~1700 to ~600.
And finally stabilized at ~420 after replacing standard texture sample nodes with HLSL Tex.Load() and using integer pixel coordinate fetching.
Pre-baked LBS (Matrix Tex Mode)
To reduce the ALU cost of reconstructing matrices per vertex,
I tried to implemente a mode that bakes the final matrix3x4 directly into a single texture (occupying 3 pixels (3*float4) per bone per frame).
The Reality
While matrix math decreased, the texture sampling count increased by 50% (3 rows vs 2).
And the complex bit-masking required to address non-continuous matrix rows in a 2D texture introduced new ALU overhead.
Pros
In scenarios where temporal interpolation is disabled, the ALU performance is slightly superior to the standard LBS mode.
DQS (Dual Quaternion Skinning)
The breakthrough in performance came with the Dual Quaternion mode.
By converting the translation and rotation into Real and Dual Quaternions (Q_real, Q_dual) in Houdini,
the shader can direct calculate WPO and no longer needs to construct or blend matrix3x4.
Performance
DQS achieved the lowest instruction count at ~395 with 4 influences per vert.
Disadvantage
DQS requires strict DQS parity between DCC and Engine to ensure same geometry.
Dismatch can cause abnormal mesh “bulging” compared to the more commonly used LBS, as the mathematical assumptions for joint deformation differ.

